Answering questions by means of Natural Language Processing
In the past year I have been working on a framework to allow users to interact with a knowledge base through written natural language. The goal is to provide a simple library that allows you to ask a question in plain english (or some other language) and receive a complete sentence for an answer. I do this in the sparse hours of free time that I have, so the project is a long way from being finished. However, I have now reached the point where the program can make a full round-trip from question to answer for a single question. This is a good moment to write about the choices I made and to explain the process.
 There are many ways to process a sentence. I am going to describe the one I chose. I am still in the middle of all this, so don't expect a finished product. I wrote it to explain the big picture.
There are many ways to process a sentence. I am going to describe the one I chose. I am still in the middle of all this, so don't expect a finished product. I wrote it to explain the big picture.
In this article I will take the following question as an example.
How many children had Lord Byron?
Follow the article to find out the answer :)
Understanding
Extract words
In the first step the words of the sentence are extracted. I have not found any use for punctuation marks at present so we can discard them. Whether a sentence is a question or a statement will be deduced from the structure of the sentence.
The product of this step is this:
[How, many, children, had, Lord, Byron]
Group lexical items
In the next step words that go together are aggregated into lexical items. The goal of this step is to find the smallest possible groups of words that still have a single part-of-speech (noun, verb, determiner, preposition, etc.). This way, compounds like "barbed wire" are now considered to be a single item. I also use this step to find proper nouns (i.e. the names of people, like "Lord Byron"). The words that are found in the lexicon are lowercased, the words that are suspected to be proper nouns are left unchanged (since there is no use to lowercase them, and I would need to uppercase them again in the production phase). This step produces this array of words:
[how, many, children, had, Lord Byron]
Parse the words to form a phrase specification
This is a big step. It is based on section 11.5 of the book "Speech and language processing" (Jurafsky & Martin) which describes parsing with unification constraints. In this step a syntax tree is created based on the array of words we just found, and a set of production rules like these:
S => WhNP VP NP (how many children had Lord Byron)
WhNP => whwordNP NP (how many children)
NP => determiner noun (many children)
VP => verb (had)
NP => propernoun (Lord Byron)
The parsing grammar has more rules, but these are the ones needed to parse our sentence.
Four choices were made at this point. I decided to go for Phrase Structure Grammar, not some other grammar, mainly because the books I happened to read treated this type of grammar much more extensively. Other grammars may work equally well, or even better, though. I chose the Earley parser, because it was said to have the best time efficiency. I have not compared it to other parsers, and those might be better in some instances.
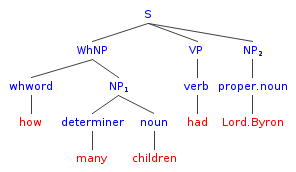
This tree represents the syntactic aspect of the parse. It does not show the features that are attached to each of the syntax tree nodes. These features provide both extra syntactic and semantic information. At the same time the sentence is parsed into a parse tree, the feature structures that are bound to each of the words in the sentence are propagated up the tree via unification with the feature structures of the production rules.
The third choice I made was to integrate semantic parsing with syntactic parsing. I did this because I figured that producing multiple resulting parse trees was not really very useful. It is a neat feat, but it is not important for my project. One would still need to chose one tree over the other in order to answer the question in the best possible way. So why not try to find the best tree immediately, and leave it at that? Adding semantic constraints to the parse process helps eliminate ambiguous trees, and I needed semantics anyway. So my strategy is to add as many constraints to the parse as I can, and consequently pick the first parse tree that comes out.
I would like to explain to you the incredible power of feature structures in a single paragraph, but I'm afraid that's impossible. See chapter 11 of Jurafsky & Martin for an extensive explanation. I added feature structures to each of the production rules, like this one:
array(
array('cat' => 'S',
'features' => array('head-1' => array('sentenceType' => 'wh-non-subject-question', 'voice' => 'active'))),
array('cat' => 'WhNP',
'features' => array('head' => array('sem-1' => null))),
array('cat' => 'VP',
'features' => array('head-1' => array('agreement-1' => null, 'sem-1' => array('arg1{sem-2}' => null)))),
array('cat' => 'NP',
'features' => array('head' => array('agreement-1' => null, 'sem-2' => null))),
),
You will recognize the production rule (S => WhNP VP NP) when you look at the 'cat' attributes. The array above can be represented like this:
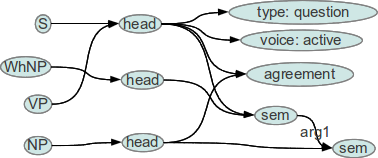
It really is as complicated as it looks. Feature structures are not simple. They form a different programming paradigm and require some time to learn. In the feature structure above, S shares all features of VP, via the head node. This means that the VP is the base node of the structure and the S inherits all of it, including its sem (semantics). You can also see that NP and VP (via S) share agreement. That is, NP and VP should have the same person and number. This makes it impossible that the sentence "How many children has we?" will pass. Finally, you can see that NP forms the first argument (arg1) of the predicate expressed by VP.
Now the feature structrures of the constituents WhNP, VP, and NP, are unified with the feature structure of the top level production rule above, and at the same time the sentence's semantics bubbles up from bottom to top.
Semantics starts at the lowest level, where each word in the language has a feature structure attached to it. Here's an example for the verb 'had' that is used in our example sentence:
'had' => array(
'verb' => array(
'features' => array(
'head' => array(
'tense' => 'past',
'sem' => array('predicate' => '*have'),
),
),
),
)
Parsing the sentence creates the following unified feature structure which we will call a phrase specification.
Array
(
[head] => Array
(
[sem] => Array
(
[predicate] => *have
[arg1] => Array
(
[name] => Lord Byron
)
[arg2] => Array
(
[category] => *child
[determiner] => *many
[question] => *extent
)
)
[tense] => past
[sentenceType] => wh-non-subject-question
[voice] => active
[agreement] => Array
(
[number] => s
[person] => 3
)
)
)
In this specification you see the sem (semantics) part that describes the predicate and its arguments. All three of them are objects that have attributes. The arg2 object contains an unknown, a variable, that is the root of the fact that this sentence is, in fact, a question. Next to these semantic aspects there are syntactic aspects, like tense and voice.
This allows me to explain the fourth choice I made: I don't create a logical representation of the sentence, but a syntactic-semantic representation, which is called a phrase specification. And this type of structure is used moreoften in language generation than in language understanding. I found the best descriptions of it in the book "Building natural language generation systems" (Reiter & Dale). This structure, which is a combination of syntactic and semantic features, keeps intact the structure of the sentence(!) and saves information about tense, voice, etc. This is all done to make it easier to create the answer, as we will see later on. But first we need to find the actual answer.
Finding the answer
Turn the phrase specification into a knowledge base representation
Now that we have the question, we need to find the answer. Luckily, these days you can find many Open Data knowledge bases on the internet that have publicly, and even free, accessible interfaces! I used one of them which I will not disclose at this point. It has a SPARQL interface. So I wrote a function that turns the phrase specification above into a SPARQL query:
SELECT COUNT(?id151) WHERE {
?id193 <http://some_enormous_database.net/object/child> ?id151 .
?id193 rdfs:label 'Lord Byron'@en
}
This knowledge base returns a data structure that tells me that the answer is:
2
The children were called Ada and Allegra [1].
")

Would it have been easier to turn our question into a SPARQL query if the representation had been a set of logical propositions? Probably not. You see, there are many ways to represent semantic information. For a simple example, the relation child(x, y) could have been represented as father(y, x). Other representations are even more different. So there will always be a conversion step between our way of representing relations and the way the knowledge base represents relations, except in the case that you write your parser uniquely for this specific knowledge base. I wanted to write a more generic framework that allowed the use different knowledge bases.
Generation
Integrate the answer into the phrase specification of the question
I would like to have the language processor give me the answer in a full sentence. We start by filling in the the answer that the knowledge base gave us into the phrase specification:
Array
(
[head] => Array
(
[sem] => Array
(
[predicate] => *have
[arg1] => Array
(
[name] => Lord Byron
)
[arg2] => Array
(
[category] => *child
[determiner] => 2
)
)
[tense] => past
[sentenceType] => declarative
[voice] => active
)
)
We modify the existing phrase specification, and fill the variable. Then we change the sentenceType from question to declarative and we're done. This is important. We don't need to think of a sentence structure to express the knowledge we have. It's already there. It's like performing Jiu jitsu on the question: use its own strength against it.
Generate a sequence of lexical items from this phrase specification
Now we need to go the opposite way. We need to create a string of words from a tree structure. That seems easy. Just use the same production rules in the reverse order. Unfortunately it is not that simple. The production rules can be used, but the feature structures need to change. I found two reasons for this:
- Generation is not a search process. If you don't specify which rules to use for generation, the processor will try many possible paths that will fail. This is a big waste of time!
- Many feature structures used for understanding just pass meaning up to the node above. If this process is reversed the meaning stays the same, and this will cause an infinite loop for recursive rules like NP => NP PP.
The essential difference between understanding and generation is:
"Understanding is about hypotheses management, while generation is about choice."
(free, after Speech and Language processing, p. 766)
Generation is a process of hierarchical choices: each choice is based on a part of the phrase specification. Let's start at the top. I will show you the top-level production rule I use to generate the answer to the question:
array(
'condition' => array('head' => array('sentenceType' => 'declarative', 'voice' => 'active')),
'rule' => array(
array('cat' => 'S', 'features' => array('head' => array('tense-1' => null,
'sem' => array('predicate-1' => null, 'arg1-1' => null, 'arg2-1' => null)))),
array('cat' => 'NP', 'features' => array('head' => array('agreement-2' => null, 'tense-1' => null,
'sem{arg1-1}' => null))),
array('cat' => 'VP', 'features' => array('head' => array('agreement-2' => null, 'tense-1' => null,
'sem' => array('predicate-1' => null)))),
array('cat' => 'NP', 'features' => array('head' => array('sem{arg2-1}' => null))),
),
),
The structure has two parts: a condition, and a rule. Only if the condition matches, when it is unified with the partial phrase specification, the rule is used to generate part of the syntax tree. The feature structure is different from the rule we saw earlier: it makes sure that meaning is distributed over the consequents. Generation is a recursive process, like understanding. First the S node is matched to the rule I just mentioned and the top-level phrase specification is unified with the feature structure of the rule. Then the process is repeated for the NP, VP and NP. And so on, until the lexical items are found.
While the understanding rules are ordered by frequency of occurrance, generation rules are ordered by decreasing specificity. The top ones have more conditions.
The result of this process is an array of lexical items:
[Lord Byron, had, 2, children]
Punctuation and capitalization
To form a proper sentence, it should start with a capital letter (which it already had in our example) and end with a period:
Lord Byron had 2 children.
That's what we wanted to hear :)
Books
The material above I found in these books. The books allow many alternative routes to follow, none of which are worked out to a great extent. After you read them, you will have some idea where to go, however.
- Speech and language processing, Daniel Jurafsky & James H. Martin (2000)
- Building natural language generation systems, Ehud Reiter and Robert Dale (2000)
- Labels
- nlp
Archief > 2012
december
- 27-12-2012 27-12-2012 10:52 - Semantic attachment
- 26-12-2012 26-12-2012 11:27 - Semantic representation
Reacties op 'Answering questions by means of Natural Language Processing'
replica louis vuitton
michael kors outlet
cheap jerseys
louis vuitton outlet sale
michael kors outlet store online
cheap soccer jerseys free shipping
cheap basketball jerseys
oakleys black Friday
cheap jordans
cheap nfl football jerseys
camping cure
uggs discount
louis vuitton handbags with scarf
cheap soccer jerseys china
cheap custom nhl jerseys from china